Many of us love synthesizers simply because these instruments, unlike any other, allow us to create novel, previously unheard-of sounds. A synthesizer is like a chemistry lab for sounds, where you can mix and match different elements to cook up unique sonic alloys. That said, it has always been difficult for synthesizers to create sounds with a level of subtlety, and variance that comes naturally for acoustic sound sources. This is the domain of physical modeling—a set of approaches to sound synthesis that aim to simulate complex behaviors of real-world musical instruments, and acoustic objects.
In this article, we will discuss what physical modeling synthesis is, and briefly outline a range of specific approaches associated with this method. We will also summarize its origins, and talk about historic and modern synthesizers that implemented physical modeling in their designs. Moreover, we will touch upon the different use-case applications of the method, including its effectiveness at recreating sounds of acoustic instruments, and its potential to transcend real-world sounds.
The Dynamics of Acoustic Instruments
Let's step back for a second to talk about acoustic instruments.
If you pluck a string on an acoustic instrument repeatedly, the sound will be quite different at each iteration. There is a convergence of multiple forces in place—the mass of the objects, the tension of the string, the intensity with which you strike it, the size of the soundboard, and the material the instrument is made of—all of these elements (and more!) continuously interplay, causing continuous changes in the sound. As musicians, we often have to work hard to find the balance between these forces to achieve the desired level of uniformity in sound. However, we still appreciate this delicate variedness in sound. This is exactly what makes acoustic and electro-acoustic instruments sound "alive."
With synthesizers, at least in their common arrangement, the opposite is often true. In most synthesizers, each time we press a key, we send a pitch value to an oscillator and trigger an envelope that dynamically opens an amplifier...and no matter how many times we press the key, we'll get consistently the same sound. This is not to say that there is no complex interaction between the components of a synthesizer. Engineers specifically worked out ways to achieve the level of stability and reliability that we enjoy in modern synthesizers. The constancy of a synthesizer is part of its design, and if we want to add instability and nuance, we usually do so programmatically.
For example, one can inject a degree of randomness with a module like sample-and-hold, so that each time you trigger a key, the timbre changes slightly. While there are a lot of interesting effects one can achieve using controlled randomness, this doesn't directly translate to the complexity of interaction between physical objects. You can use subtractive, additive, or FM-based methods to mimic the timbre of a guitar, but they don't answer the question of what actually happens when you pluck a string with your finger, and how is it different from when you hit it with a mallet or bow it. This is where physical modeling comes in.
So...What is Physical Modeling Synthesis?
Physical modeling synthesis is a collection of methods that employ mathematical models to simulate the physical properties of acoustic instruments or other sound-producing objects. In particular, a mathematical model is used to describe the physical properties of a particular object, including its shape, size, material, and how it vibrates or resonates when excited. Typically, the approach involves dividing the modeled object into a collection of parts. At the very basic, there are two components: an exciter, and a resonator.
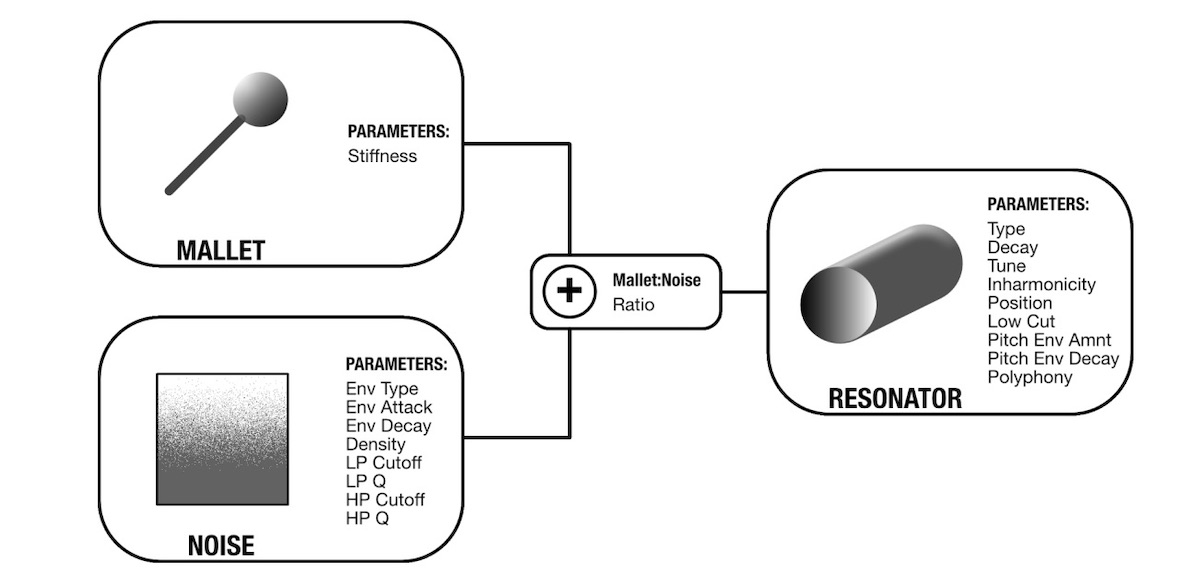
[Above: a diagram detailing the exciter & resonator structures in Intellijel/AAS Plonk—a Eurorack module based on principles in physical modeling synthesis.]
An exciter simulates the initial energy source that forces the object to vibrate. We do not hear its sound directly, but it is reflected in how the model responds. The exciter is usually dependent on the instrument modeled, and it can be shaped to simulate the behavior of a bow, a plucking mechanism, a breath, or an airflow. In practice, an exciter can be something as simple as a click, a shaped noise, or even a pre-recorded audio sample.
A resonator represents the acoustic resonant properties of a modeled instrument. It expresses its characteristic frequencies, harmonic balance, as well as how the sound decays over time. Depending on the context, a resonator model can represent the body of a stringed instrument, the air column of a wind instrument, or a membrane and a shell of a drum. The function of a resonator can be fulfilled by a collection of resonant filters, a delay line with feedback, or a combination of different elements.
While physical modeling synthesis is possible in the analog realm, because of the necessary degree of precision, and an often extensive number of required components, the digital domain offers a much more efficient framework for the approach. Thus, almost certainly, if a synthesizer employs a physical modeling method, it is likely a digital instrument.
We should also emphasize here that although we generally use the term physical modeling synthesis to describe simulations of acoustic instruments and other real-world sound objects, in reality, there is a wide range of different distinct methods that fall into this category. This is logical, since a stringed instrument, a drum, a saxophone, and a voice have unique idiosyncrasies, and require different mechanisms of realization. Thus one approach can be suitable for one instrument, but not necessarily best for the other. In a later section, we will take a look at a few specific examples of physical modeling methods.
And before we move into further discussion, It is important to note that while the method intends to simulate the behavior of the physical objects, once the model is created, we are no longer bound to the confines of the physical realm. Thus, physical modeling allows us not only to simulate acoustic instruments—but also offers us a unique opportunity to explore bizarre, abstract ideas. For example, what if you pluck a string at nearly audio rate? Or, perhaps, you want to try an instrument whose body gradually expands as you play it? Physical modeling synthesis makes this possible. Superphysical modeling, if you will.
The Origins of Physical Modeling Synthesis
 A period illustration of Faber's Euphonia from PT Barnum advertisement—image via Princeton Graphic Arts
A period illustration of Faber's Euphonia from PT Barnum advertisement—image via Princeton Graphic Arts
The earliest form of physical modeling synthesis was speech synthesis. For several centuries, humans have attempted to create machines that could speak. And at different times, with varied degrees of success, they have accomplished that. In 1769 the Austro-Hungarian inventor Wolfgang von Kempelen developed the first anatomically-based and functional mechanical speech synthesizer, "The Speaking Machine." The instrument was assembled with a set of rudimentary materials like kitchen bellows, a reed removed from a bagpipe, and a clarinet bell. While simple, the instrument was able to produce a range of vowel sounds, and with some manual interference, a performer could extract more articulated inflections. Kempler continued to improve the mechanism up until he died in 1804. He created two more significant revisions, with the last one fully capable of speaking entire sentences in multiple languages.
Following the footsteps of Kempelen's machine, other speech synthesis instruments started to emerge. Among them was the Euphonia, created by Joseph Faber, which was first publicly exhibited in 1846. Euphonia featured a complex mechanism comprising a telegraphic line, a series of bellows, plates, and chambers, a replica of a human face, and 17 levers that could be operated to combine a variety of tones into any words from all of the European languages.
[Above: a video demonstration of Homer Dudley's Voder.]
Nearly a century later, Homer Dudley developed an analog model of the vocal tract at Bell Labs, which became the active part of the first electronic speech synthesizer—the Voder (1939). Similarly to Euphonia, Voder’s circuit was controlled by a series of keys, as well as wrist bars, and a pitch pedal. With highly skilled and coordinated gestures, the instrument could produce nearly any voice-like sound, with varied intonation, and at different octave ranges. The research on speech synthesis at Bell Labs didn’t end with Voder, and in 1961 Max Mathews-led team realized the concept in the software realm. Mathews cooperated with the engineers who created the Kelly-Lochbaum vocal tract model to “teach” computers how to sing. The result of this work was the famed computer-voice rendition of the “Daisy Bell,” also known as “Bicycle Built For Two”—a piece that inspired the last moments of the HAL computer in Kubrick's 2001: Space Odyssey.
Although speech synthesis certainly was the original form of physical modeling, the overall branch of physical modeling synthesis as we know it today would only start to be considered a feasible sound design technique once the processing power of computers increased enough. One of the first influential texts on the matter was published in 1971 by Lerajen Hiller and Pierre Ruiz. In "Synthesizing Musical Sounds by Solving the Wave Equation for Vibrating Objects," the authors put forward the concept of using mathematical models to simulate the behavior of acoustic objects.
However, things really started to take off with the invention of the Karplus-Strong technique in 1983 at Stanford's Center For Computer Research In Music and Acoustics (CCRMA). Invented by Alexander Strong, and then analyzed by graduate student Kevin Karplus, the algorithm provided a powerful means to synthesize a realistic model of a plucked or hammered string. It was later extended by Dr. Julius Orion Smith III into digital waveguide synthesis—a comprehensive framework for synthesizing all kinds of acoustic objects, including tubes, bells, drums, plates, and strings. It is this method that the majority of physical modeling synthesizers implement to this day.
 Dr. Perry Cook—image via CalArts school of music website.
Dr. Perry Cook—image via CalArts school of music website.
Dr. Perry Cook is another researcher who contributed greatly to the field of physical modeling synthesis. Under supervision from Julius Smith at CCRMA, he co-developed the influential Synthesis Toolkit Library (STK). Later he moved to teach at Princeton University, where he founded Princeton Sound Lab, and co-founded the Princeton Laptop Orchestra (PLOrk). Presently, Cook acts as an advisor to various music technology companies and continues to publish articles and books on physical modeling synthesis and psychoacoustics.
The developments of physical modeling techniques piqued the interest of the Japanese brand Yamaha, and in 1989 the company signed an agreement with the school for joint development of the digital waveguide method. This led to the release of the Yamaha VL1 in 1993—the first commercially available hardware instrument entirely based on the physical modeling method. Impressive, even by today's standards, VL1 was an amazingly expressive instrument that can be programmed to produce nuanced sounds that lie anywhere on the spectrum from realistic simulations to completely abstract and bizarre. The company would later follow up with a series of physical modeling instruments which included VL1-m, VL7, and VL70-m.
[Above: a video demonstration of the Yamaha VL-1 physical modeling synthesizer.]
At the time of the release of the VL1, it was speculated that physical modeling synthesis would become the next big thing—however, its popularity didn't spread as much, and it was FM synthesis that continued to dominate the landscape. Primarily, there were two reasons. One, creating nuanced and realistic models of physical phenomena required quite a lot of computational power, which was expensive, and thus making such instruments, and consequently obtaining them, required serious investments. Moreso, FM synthesis was already quite powerful and effective in tackling many desired sound design tasks, so the transition was debatable. Second, the true expressiveness of the physical modeling approach required an extended controller paradigm, one that went beyond the note-on/velocity and even aftertouch. While Yamaha already supplied the VL1 with a BC2 breath controller, the common MIDI controllers at the time lacked many of the expressive functions that we get to enjoy today. These factors certainly hampered the availability of physical modeling methods to the wider public at the time.
As we overcome the technological limitations of the past, we are starting to see more and more physical modeling-based instruments. Ableton Live, presently one of the most popular music production programs, offers several devices based on the method—Tension, Collision, and Corpus—all co-developed with Applied Acoustics Systems, the software company that specializes in the approach. AAS also produces a range of physical modeling plugins independently, with Cromaphone being one of the most well-known. The line of unique semi-modular software instruments from Madrona Labs features Kaivo—a powerful synthesizer that blends granular and physical modeling synthesis. Physical modeling is also explored by the indie music software maker Giorgio Sancristoforo, namely with the TAMS synthesizer in his famed Gleetchlab, and with the Substantia.
[Above: a video demonstration of Madrona Labs Kaivo, a physical modeling-based virtual instrument.]
The world of hardware also has seen a spike in physical modeling-based instruments. Now defunct Mutable Instruments brought the method into the modular ecosystem with iconic modules Elements and Rings. Making the designs open source also ensured that these modules will continue to be produced by other manufacturers, i,e. After Later Audio makes Quarks, Atom, and Resonate. Several other Eurorack brands also offer original physical-modeling designs, including Pluck and Bell from 2hp, Plonk from Intellijel, and Surface from Qu-Bit Electronix. The method is also employed in Quantum and Iridium—a pair of marvelous mega-synths from Waldorf.
Popular Physical Modeling-Based Eurorack Modules
 Qu-Bit Electronix Surface Physical Modeling Voice 10hpAs low as $349.00Multiple Options Make a selection for stock info
Qu-Bit Electronix Surface Physical Modeling Voice 10hpAs low as $349.00Multiple Options Make a selection for stock info-
- Intellijel Designs Plonk 12hp$349.00Backorder Reserve your order today!
Out of Stock
We're awaiting our next batch of this item. Pre-order to reserve your place in line and we'll fulfill your order as soon as we receive our shipment



Types Of Physical Modeling Synthesis
We have already specified that physical modeling synthesis encompasses a wide range of different sound design approaches, so in this section, we would like to outline a few of the most common forms of it. While we can't get into the depths of individual methods, we will provide general descriptions of how a particular approach is implemented.
Let's start with the aforementioned Karplus-Strong synthesis. As we have said, the purpose of this method is to simulate the behavior of a vibrating string. The algorithm involves using short bursts of noise or individual clicks as an exciter which is then processed through a short delay line with a feedback loop. Changing the delay time is proportional to the length of the string and inversely proportional to the pitch, and the amount of feedback corresponds to the decay time of a string.
Digital Waveguide synthesis relies on the principles of waveguide theory to simulate the effect of sound propagating through various physical mediums. This includes strings, plates, tubes, and membranes. In this method, we can modify the virtual properties of the exciter signal, and the delay line to match the particular properties of physical objects such as their size, diameter, shape, material, mass, etc. While similar to the Karplus-Strong algorithm, DWS offers much more nuance and flexibility, and as such, it is used to create realistic versions of a wide range of acoustic instruments.
Another common form of physical modeling synthesis is Modal synthesis. Modal synthesis features a similar "exciter-resonator" structure as the methods above, albeit it is not a delay line that makes up the resonator, but a series of resonant bandpass filters tuned to match the resonant frequencies of a particular acoustic object. It is effectively similar to additive synthesis, implying that any complex sound can be decomposed into a series of sine wave partials. This makes modal synthesis amazingly flexible, as technically it can be used to simulate any acoustic timbre with a great level of detail. This is the method used in the earlier mentioned Mutable Instruments modules.
Speech synthesis in itself is a particularly dense subject that primarily splits into two distinctive approaches: formant synthesis and concatenative synthesis. Formant synthesis involves manipulating the frequency spectrum of a source waveform, i.e. a pulse or noise waveform, using digital filters that simulate the resonances of the vocal tract. By boosting specific frequency bands we can generate a full range of vowels, which are then further shaped and modulated to produce the desired sound. Concatenative synthesis works by analyzing the spectral characteristics of a large database of pre-recorded sounds, such as speech, music, or environmental sounds, and breaking them down into small grains. But unlike typical granular synthesis, these grains are then indexed and stored in a database, along with information about their pitch, duration, and other attributes. When a new sound is to be generated, the system selects and concatenates the appropriate grains from the database, based on their spectral similarity to the desired sound. The resulting sound is a combination of individual units, which can be manipulated in real-time to produce a wide range of sounds and textures. If you wish to experiment with speech synthesis, we highly recommend checking out the highly entertaining pink trombone instrument designed by Neil Thapen.
It also has to be mentioned that other synthesis methods can be incorporated into physical modeling at various stages. We've already seen the implementation of the additive technique in the case of modal synthesis. Another example is granular synthesis, which can be amazingly useful in simulating complex physical behavior, i.e bouncing, swarming, etc. In fact, granular synthesis is commonly used in order to define the behavior of the exciter stage in various implementations of physical modeling—the the aforementioned Kaivo by Madrona Labs for a great example of how this can work.
A Note On Controllers
It is important to emphasize how important expressive controllers are for physical modeling synthesis. Think about what makes the experience of playing an acoustic or electro-acoustic instrument so satisfying—it responds immediately to every slight modification of the gesture. Therefore, MIDI Polyphonic Expression (MPE) technology is particularly useful in the case of physical modeling synthesis.
By obtaining and mapping polyphonic pitch bend, pressure, aftertouch, and other parameters we can make virtual instruments not only sound realistic but also feel as such. Hence, we strongly encourage you to integrate expressive controllers into your explorations of physical modeling synthesis (or any other form of synthesis for that matter).
Pros And Cons
Compared to many other approaches to sound synthesis, physical modeling is relatively new. Although the promising potential of the method was evident even in the early '90s, we are just beginning to explore the full range of possibilities this approach offers. When discussing the pros and cons of the method, we have to consider the unique position it occupies. While other techniques aim at synthesizing timbres that are similar to those of acoustic instruments, the inherent claim of physical modeling is that it can result in realistic virtual alternatives to such. So on a case-by-case basis, we can judge its effectiveness in that realm.
One of the biggest hurdles of the method is the requirement of high amounts of processing power. And even though we are doing much better today than even twenty years ago, there is still notable room for improvement. It is apparent, though, that with the increasing power of digital technology, the line that divides the worlds of real and virtual, both in the character of sound and experience, will get blurrier. We don't know exactly what future musical instruments will be like, but it sure looks like physical modeling synthesis will be a part of that future.
Even More Physical Modeling-Based Instruments
-
-
- Waldorf Iridium Desktop Digital Synthesizer$3,499.00In Stock Available immediately!