If you think about it, nearly every type of sound synthesis can be linked to a macro-level scientific concept or discipline. Subtractive and additive synthesis harness the basic laws of mathematics; granular synthesis draws inspiration from particle physics; physical modeling is steeped in acoustics; chaotic synthesis sonifies its eponymous theory; and FM synthesis reflects ideas from wave physics.
Using this style of classification, we find concatenative synthesis at the crossroads of signal processing and data science. The evolutionary roots of the concatenative synthesis stretch back to the earliest tape music. However, it wasn't until the late 1990s that the digital data-driven method, as we know it today, first appeared. Since then, the technology, algorithms, and overall understanding of this synthesis method have evolved dramatically. Currently, I am not aware of any hardware instruments based on this technique; however, software implementations are becoming increasingly practical and accessible.
My goal with this article is threefold. First, I aim to introduce concatenative sound synthesis, outlining its principles, range of applications, and historical development. Second, I want to highlight several presently available tools to help you get settled in the world of concatenative sound synthesis. Lastly, I'll discuss a few use cases to paint a better picture of the practical and creative capacity of the method.
So What Is Concatenative Sound Synthesis?
In simpler terms, concatenative sound synthesis, often abbreviated as CSS or C-Cat, involves dividing a sound recording into individual units and recombining them to create new sounds. This definition, however, is vague enough to apply to other techniques like granular synthesis and resynthesis. There's indeed some overlap here. Concatenative synthesis can be seen as a sub-branch of both, with unique differences. First, regarding similarities to resynthesis, CSS can involve the systematic "reconstruction" of sounds…however, unlike in resynthesis, the sound is reconstructed by recombining chunks of recorded audio. In the jargon of CSS, these chunks are called sound units, and typically they are longer in duration than the sound grains of granular synthesis, encompassing entire phrases and patterns. More importantly, CSS distinguishes itself as a data-driven method, driven by several levels of audio and data analysis.
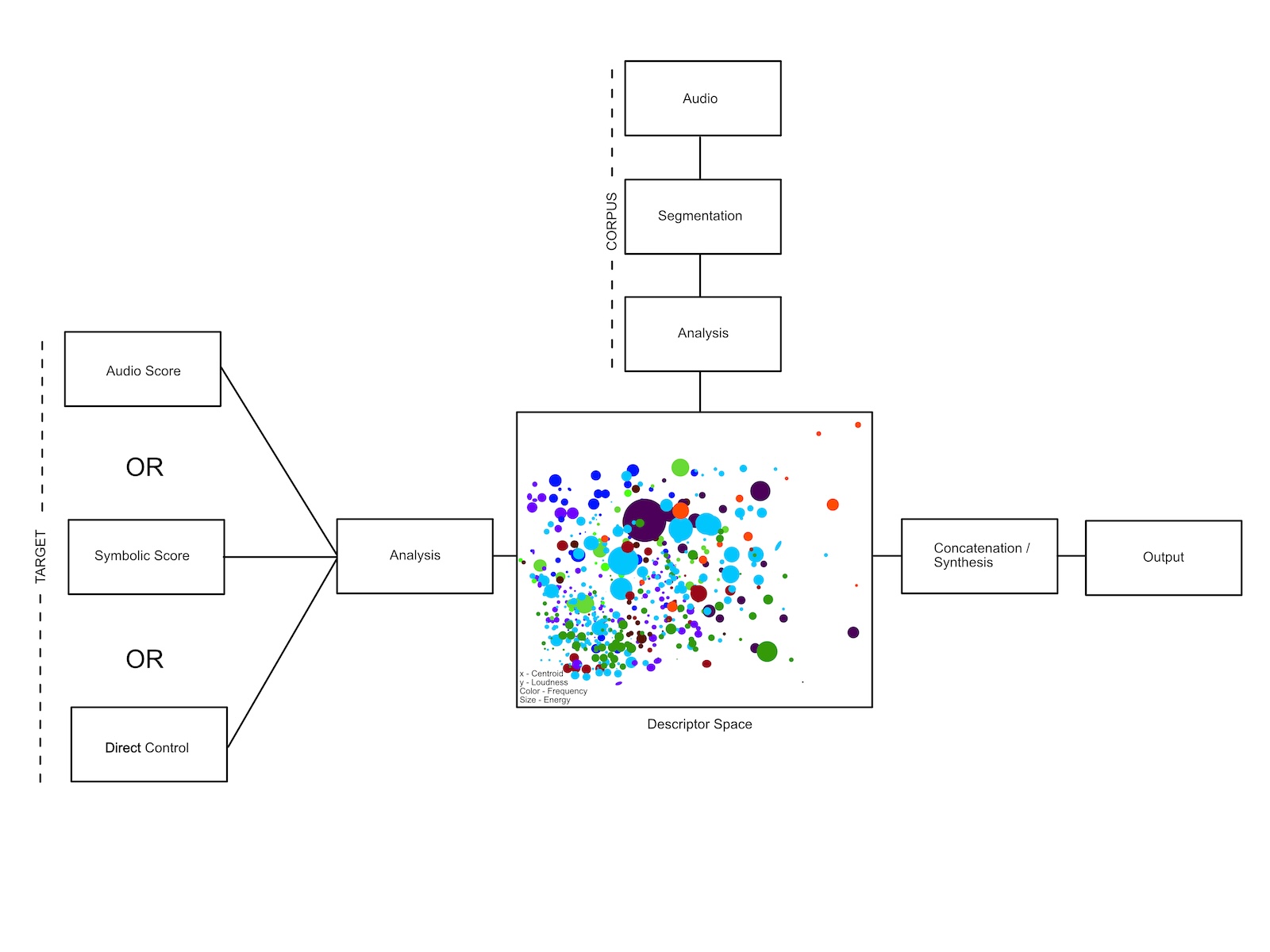
To better understand what all of this means, let's break down the process into discrete stages. First, we collect and select audio samples to create a sound corpus (a database of sounds and related metadata). The audio can come from a single source, like different notes of one specific instrument, or be more diverse and heterogeneous (a collection of unrelated sounds). Next is segmentation: slicing audio into smaller sound units. This is handled via a variety of algorithms selecting for either onset or silence detection, energy threshold, spectral or rhythmic content, or pitch values. Each sound unit is then analyzed according to an arbitrary set of descriptors such as pitch, timbre, spectral content, dynamics, duration, or other temporal features. The units and their descriptors are further synchronously organized into a searchable database or corpus, which is later used to construct new sounds.
Sound generation involves specifying a target through desired output features, using a controller to scan the database, or feeding an audio signal into the system—this is called an audio score. During the concatenation stage, multiple segments are seamlessly "stitched" together to match the specified target as closely as possible.
The sonic outcomes of concatenative synthesis are diverse, including uncanny valleys of sound-morphing, hybrid instruments, a range of worldly and otherworldly textures, ever-evolving sonic environments, rhythmic landscapes, and much more. This makes concatenative synthesis particularly suitable for sound design, computer-assisted composition, improvisation, and installation art. As composer and researcher Rodrigo Constanzo describes in his C-Cat software C-C-Combine, concatenative synthesis allows you to "play anything with anything."
A Bit Of History: Tape Music
The concept of creating music by stitching together a variety of sounds isn't new. Nearly as soon as humanity figured out how to record audio on magnetic tape, composers, artists, and sound researchers began exploring the creative potential of this medium, using recorded sound as a fundamental element of their compositional strategies. Among the plethora of musical works and ideas from the last century, some stand out as definitive precursors to CSS.
At the dawn of electronic music, around the early 1950s, two distinct philosophies emerged: musique concrète, pioneered by French composer and broadcast engineer Pierre Schaeffer, and elektronische musik, championed by composer Karlheinz Stockhausen. Stockhausen focused on creating music from synthetic sounds produced by oscillators, filters, and other proto-synthesizer equipment. Schaeffer’s approach, on the other hand, involved finding musicality in concrete sound sources. His method centered around recording natural and industrial sounds onto tape, then editing and splicing these recordings to create new compositions.
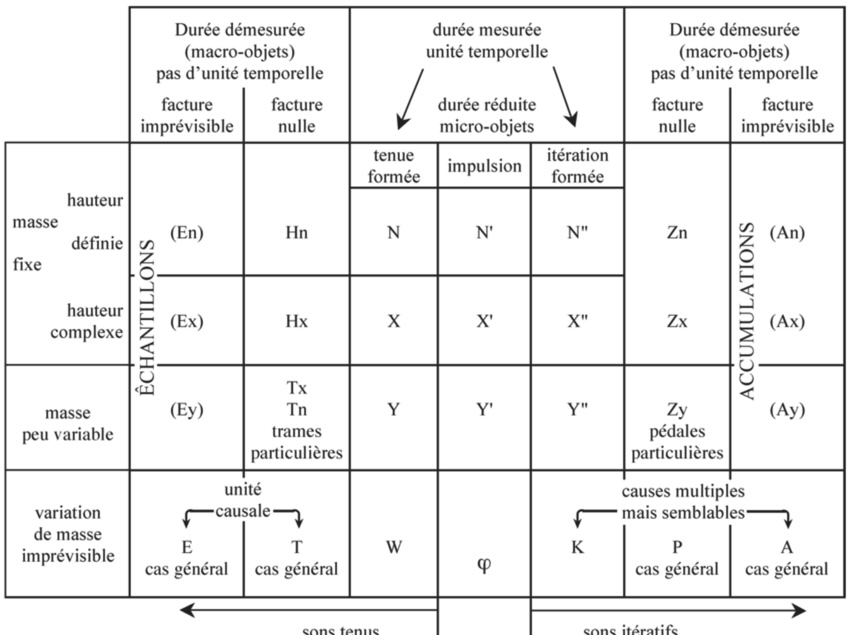
[Above: Pierre Schaeffer's Tableau recapitulative de la typologie (TARTYP), from Traité des objets musicaux—a proposed system for the categorization of sounds. Reproduced by Lasse Thoresen for use in a variety of papers about spectral music and spectromorphology/phenomenological approaches to musical analysis.]
The tape manipulation techniques developed during this period, which involved splicing, reversing, and changing pitch by altering speed, layering, fading, and crossfading, have become foundational in audio work, and are now embedded in the basic tool set of any Digital Audio Workstation (DAW). However, more relevant to our discussion is Schaeffer’s concept of the "sound object" (objet sonore), a central idea in musique concrète. Schaeffer proposed considering sounds independently of their sources or the contexts in which they were produced, focusing instead on their inherent qualities and structures. His approach involved recording a variety of sounds, analyzing, and organizing them based on acoustic properties like pitch, loudness, timbre, and rhythm for later retrieval during the process of composition. While this manual method differs from today's fast algorithmic segmentation in CSS, the philosophies between the two methods are linked.
Musique concrète was a pivotal movement, yet the development of CSS was further shaped by two other seminal figures in electronic music history: John Cage and Iannis Xenakis, each contributing distinctively to its evolution. Cage introduced concepts like chance operations, and indeterminacy, as well as prepared techniques to modern music. His 1952 composition Williams Mix is particularly noteworthy for its influence on CSS. Using a borrowed tape machine from Louis and Bebe Barron, Cage devised a complex compositional process using chance operations to determine editing, splicing, and sequencing details, resulting in an intricate assembly of over 600 tape segments categorized into six groups: city sounds, country sounds, electronic sounds, small amplified sounds, as well as manually, and wind-produced sounds.
Iannis Xenakis, a Greek composer, mathematician, and architect, is known for incorporating stochastic processes, statistical analysis, algorithms, and mathematical models into his compositions. His influence extends across computer music, including CSS. Notable works like Pithoprakta (1956), Diamorphoses (1958), and Analogique A-B (1959) resonate with CSS concepts. In Pithoprakta, Xenakis used statistical mechanics and probability laws to convert gas particle behavior into music. Diamorphoses involves shuffling sound segments from natural field recordings to create evolving sound masses, while Analogique A-B explores constructing soundscapes by reassembling sound grains and blurring the line between acoustic and electronic sounds.
Finally, it’s important to recognize the diverse creative approaches to working with pre-recorded sound that have been emerging since the 1970s. From phrase sampling in hip-hop and electronic dance music to John Oswald's plunderphonics, the ironically psychedelic collages of Frank Zappa, Roger Linn's MPC, and a variety of digital samplers, all these developments have enriched our understanding and approach to working with audio samples. Concatenative sound synthesis lies within this continuum, representing a fusion of ideas, philosophies, and practices that culminate in a potent and expressive method for innovative sound design, performance, and composition.
Another Bit Of History: Speech Synthesis and Beyond
Although tape music and recorded sound played a pivotal role in the evolution of Concatenative Sound Synthesis (CSS), they weren't its only influences. Decades before CSS was formally conceptualized, similar approaches and technologies were pivotal in speech synthesis. As we explored in our article on physical modeling synthesis, the quest to make machines speak has been a human fascination long before the industrial age, driven by the desire to understand the complexity of the human voice, explore machine intelligence, and, frankly, to dazzle and astound audiences.
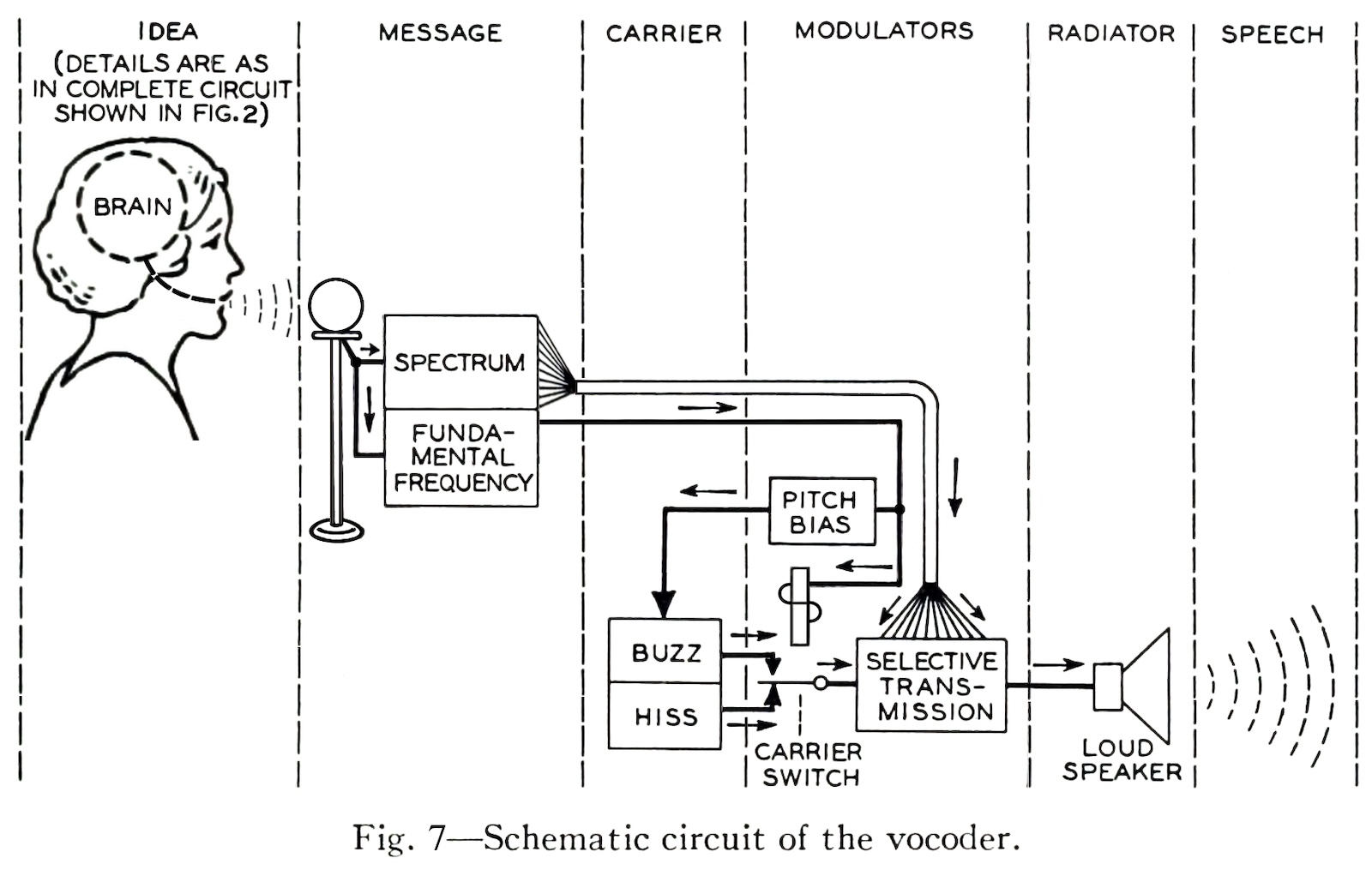
[Above: conceptual diagram of Homer Dudley's vocoder system.]
One of the earliest and most significant devices in this narrative was the Vocoder ("voice encoder"), developed by engineer Homer Dudley at Bell Laboratories in the 1930s. Dudley's groundbreaking idea was that human speech could be broken down into discrete components: the vocal cords producing a continuous tone, shaped into formants by the throat, and further articulated by the mouth, teeth, tongue, and sinuses. Dudley's Vocoder analyzed human speech, breaking it down into frequency components via bandpass filters, and then transmitted these to oscillators tuned to corresponding frequencies. Initially intended for telecommunications to compress voice signals for long-distance communication, the Vocoder eventually found its way into the creative domain (as famously demonstrated in Kraftwerk's "Autobahn"). Dudley's work underscored the concept of deconstructing sound into identifiable features for synthetic reconstruction.
The arrival of computers and digital signal processing in the 1970s marked the next significant milestone. The growing processing power of digital machines fostered new synthesis methods, including concatenative speech synthesis in the 1980s. This method stored and manipulated vast databases of pre-recorded speech units, ranging from phonemes to larger patterns, concatenated in response to target speech parameters. The goal was to achieve more natural-sounding speech, with early systems like Dennis Klatt's DECtalk, the MBROLA Project, and Bell Labs' various systems laying the groundwork. These techniques were even employed in early versions of voice assistants like Apple's Siri and Amazon's Alexa.
Recognizing the potential of data-driven sound synthesis, music technology researchers began developing digital musical systems utilizing this method in the early 2000s. One of the first was the Caterpillar system by Diemo Schwarz, an IRCAM-affiliated composer-researcher. Introduced in 2000 at the COST-G6 Conference on Digital Audio Effects in Verona, Italy, and designed in Max/MSP, Caterpillar excelled in handling large, heterogeneous sound databases. Its philosophy was simple: the larger and more diverse the database, the more likely it was to find matching segments for the target, resulting in more natural-sounding output. The system employed two segmentation algorithms: automatic alignment with musical scores and instrument corpora, and blind segmentation for free resynthesis. This yielded intricately layered and dynamically complex sounds, and high sensitivity and responsiveness to expressive control.
In 2001, Aymeric Zils and François Pachet introduced the Musaicing system, inspired by John Oswald's compositional approach. Capable of handling databases with over a hundred thousand samples, Musaicing differed from Caterpillar's focus on smooth transitions, opting for a constraint-based selection approach. This allowed for a more flexible and varied sample organization, for example allowing to set constraints for sample uniformity or the probability of including percussive sounds.
Since then, data-driven sound synthesis has branched out in various directions. In his article "Concatenative Sound Synthesis: The Early Years," Schwartz categorizes the development of the method into seven distinct groups. The first group comprises manual approaches, showcasing the work of renowned artists and composers like Pierre Schaeffer, John Cage, John Oswald, and Iannis Xenakis—we've talked about it. The second group, defined as fixed mapping, includes data-driven techniques that do not utilize descriptor analysis, such as digital sampling and granular synthesis. The third category, spectral frame simulation, employs Fast Fourier Transform (FFT) frames as segments, aiming to match them with the target based on spectral shape similarity. A notable example is Miller Puckette's Input Driven Resynthesis (2004) project.
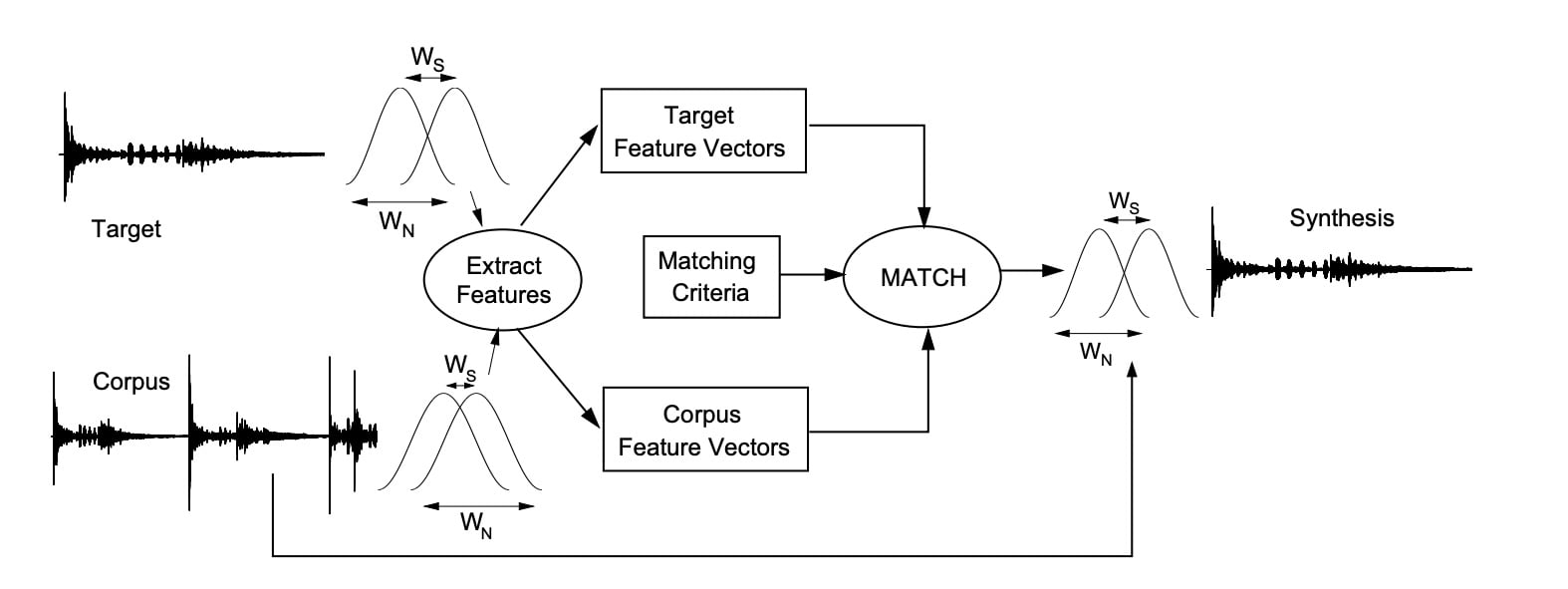
[MATConcat conceptual diagram, as seen in Bob L. Sturm's 2004 paper MATConcat: An Application for Exploring Concatenative Sound Synthesis Using MATLAB.]
The fourth group involves instruments based on segmental similarity, where units are matched to a target through the analysis of low-level descriptors. This group includes Steven Hazel's Soundmosaic (2001) and the open-source Matlab extension MATConcat. The fifth category is defined by real-time performance-oriented unit selection, relying on descriptor analysis of diverse sources. A prime example is the CataRT (2005) system by Schwartz, now part of the IRCAM MuBu package for Max/MSP.
The sixth group utilizes high-level descriptors for targeted or stochastic unit selection. In 2003, researchers Michael Casey and Adam Lindsay proposed using MPEG-7 metadata creatively for audio mosaicing. The final category features fully automatic high-level unit selection, as seen in systems like Caterpillar and Musaicing. These groups collectively illustrate the diverse and evolving landscape of Concatenative Sound Synthesis.
Okay, enough of history for now. In the next two sections, I will focus on some currently available tools for engaging with the CSS, and practical applications of the method.
Concatenative Sound Synthesis Now
One of the most significant advancements in data-driven sound synthesis over the past decade is the integration of machine learning and artificial intelligence algorithms into the process. This has led to substantial improvements, from more efficient handling of large databases and enhanced sound quality to innovative control systems and expanded real-time applications. Interestingly, while aspects of concatenative synthesis are increasingly present in commercial software plugins—such as XLN Audio's XO and the intelligent browsing system in Ableton Live 12—the most engaging and creatively fulfilling aspects, namely the actual synthesis of sounds, are still largely found within audio programming environments like Max/MSP, Pure Data, and SuperCollider. Familiarity with these platforms is beneficial for those interested in delving deeper into CSS. However, even if these environments are new to you, there are still ways to explore this method, which I will discuss shortly.
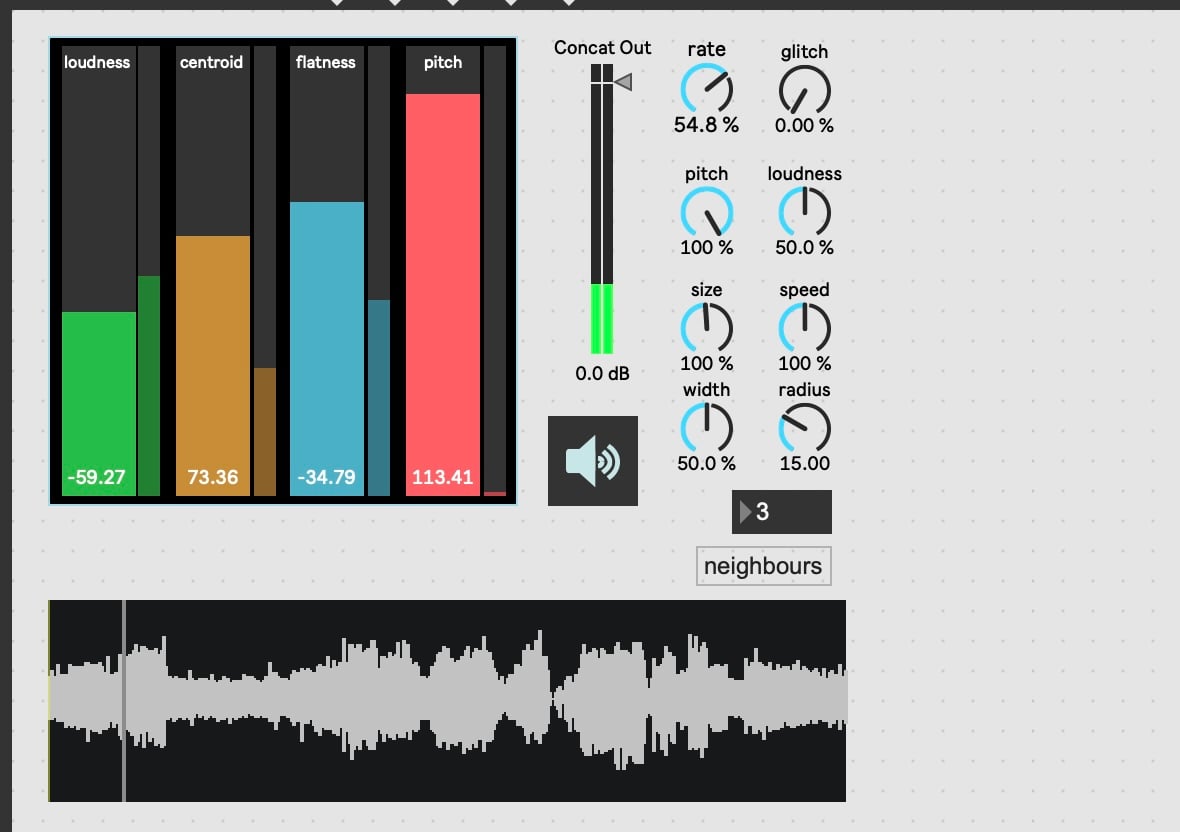
[Above: simple SP Tools setup in Max/MSP.]
My personal journey with CSS has involved a couple of frameworks within the Max/MSP environment. One notable example is the SP-Tools package developed by Rodrigo Constanzo. Leveraging the Flucoma project, SP-Tools provides a suite of optimized machine-learning tools for real-time, low-latency interaction. Initially designed for Sensory Percussion sensors, the project has since evolved to accommodate any type of audio or control input. This package offers an accessible entry point into CSS, along with a range of tools for audio analysis, clustering, classification, processing, synthesis, modeling, and more. Importantly, SP-Tools, while currently exclusive to Max, is part of the Flucoma project, which extends to SuperCollider and Pure Data, making its functionality broadly accessible with some effort.
Another significant system I've explored in the context of CSS is IRCAM's MuBu, another comprehensive Max extension. Initiated by musical gesture-interaction researcher Norbert Schnell in 2008, MuBu enhances the Max environment with a powerful multi-buffer (hence the name) capable of holding multiple layers of synchronized tracks of various data types, such as audio, sound descriptors, segmentation markers, tags, music scores, and sensor data. This makes it an ideal platform for CSS, particularly for realizing Diemo Schwarz's CatART system with ease and flexibility. For those less inclined toward Max programming, IRCAM also offers a Max-for-Live adaptation, SKataRT. While it's a paid and somewhat less flexible option, it offers ease and immediacy of use in return.
CSS: Art and Practice
Throughout this article, I've noted the potential of Concatenative Sound Synthesis (CSS) for producing rich, layered, and natural-sounding textures, as well as its distinctive resynthesis method. However, we haven't fully delved into its real-world applications. In this section, I aim to discuss how CSS can be integrated into various workflows. I will also share my personal experiences, demonstrating how this digital method has been a rewarding and flexible tool for enhancing physical instruments and analog synthesizers. Additionally, I'll provide audio examples to illustrate these points.
Let's start with the more apparent aspects. The concatenative approach's reliance on audio samples means the sonic palette it offers is virtually limitless. The output dramatically changes depending on the contents of the corpus. Moreover, the additional analysis stage, which contextualizes and organizes the sounds, makes CSS ideal for creating evolving, generative content. This is especially beneficial in durational algorithmic composition, sound installations, interactive systems, and sound design, be it for music, film, or gaming—particularly when adapting sound to fit an arbitrarily long timeframe.
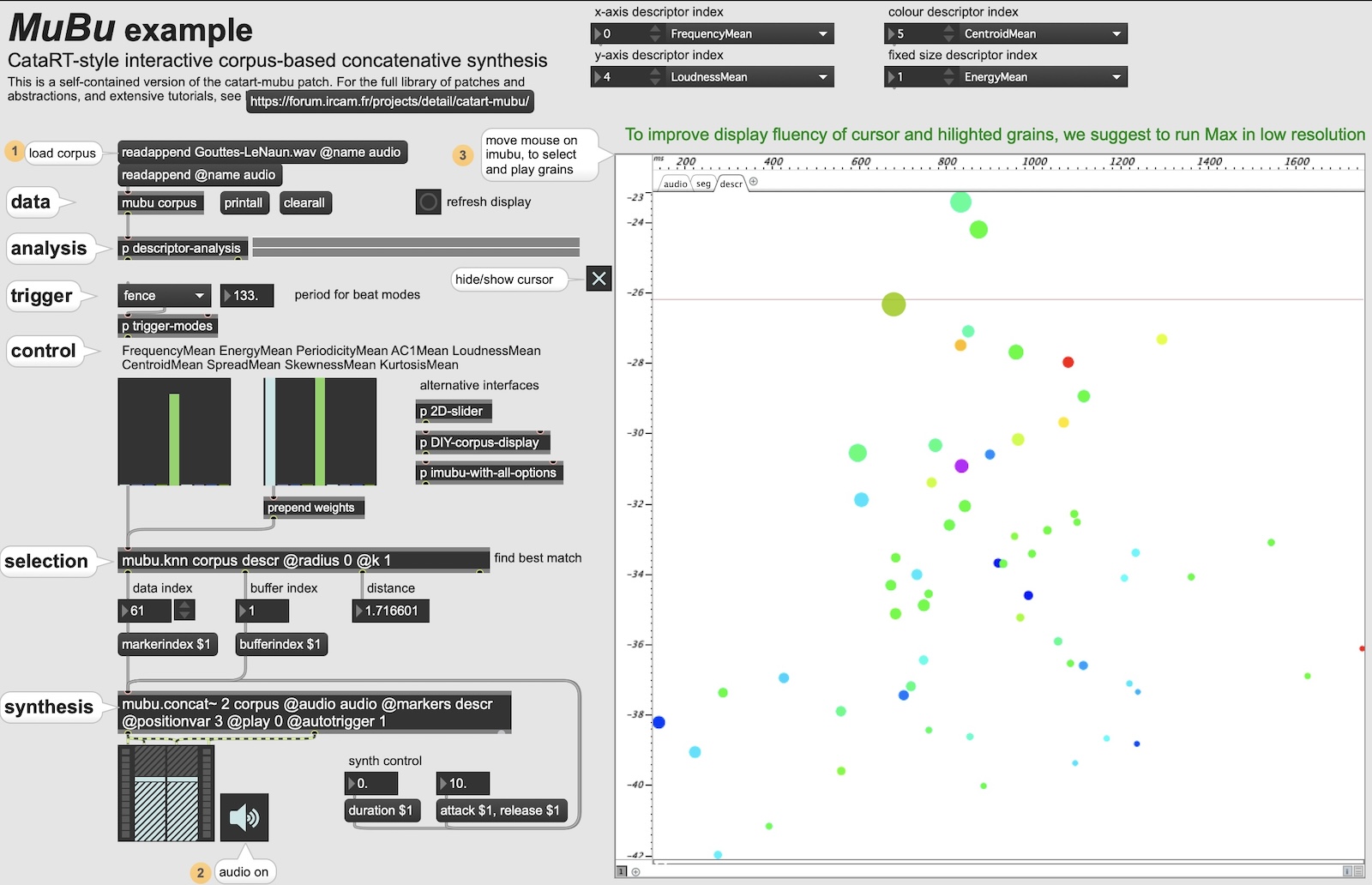
[Above: example CatART setup in Max/MSP.]
Programs like CatART are exceptionally adept at creating complex audio collages. Capable of handling large, long audio files, my experiments have ranged from loading complete musical pieces (plunderphonics-style) to curated collections of synthesizer sequences and sampled acoustic instruments. The emergence of hybrid sonic forms from these mixes has been continuously surprising. Adding layers of modulation to CatART’s parameters introduces further dynamic complexity to the results.
Finally, the potential for real-time resynthesis opens up a plethora of creative possibilities for live use. This can involve creating novel sounds from existing or live-generated sources, using instruments like guitars or drums to drive the synthesis process. Unlike simpler audio-controlled synthesis that requires source sound simplification for more accurate pitch detection and envelope following, CSS’s comprehensive descriptor system allows the use of structurally complex source sounds and greater freedom in musical expression. A strummed guitar chord processed through a series of effects, for instance, can still yield meaningful output.
An intriguing setup I discovered involved using a chaotic synthesizer as the target. I've employed Ciat-Lonbarde Plumbutter, and a Serge panel, however any device capable of crackling, droning, squealing, and responding to gestural interactions will do. In essence, it is as if the synthesizer becomes both a sound source and a controller. For the corpus, I experimented with various singing bowls and a rattling shaker. When these were matched to the erratic fluctuations of the Plumbutter, the outcome was its hauntingly resonant shadow.
Conclusion
Data-driven approaches to audio creation are on the rise, propelled by advancements in machine learning algorithms. This article has outlined the essence of Concatenative Sound Synthesis, its historical background, current methodologies, and a range of creative applications. However, it's important to note that this overview is far from comprehensive. CSS is a relatively new and continually evolving field.
As with all such articles, my primary aim is to familiarize, demystify, and inspire engagement with this particular form of sound synthesis. For those eager to explore CSS further and learn more about the concatenative approach, I recommend starting with the writings of Diemo Schwarz.